Writing a Gemini Search Engine
- HariharanI recently signed up for a free AWS account and was quite surprised at the number of services that were being offered. I didn’t want to waste this opportunity and decided to build a small project to make use of it. I have been exploring geminispace quite a lot lately and thought it would be a good project to build a search engine for it.
Gemini
Gemini is a new application layer protocol, a lightweight and privacy-oriented alternative to HTTP. You can find the entire spec here and it is beautifully minimal. Most Gemini clients are terminal-based and it is refreshing to just sit and read blogs without any distractions. And because Gemini is a new and niche protocol, most people in the geminispace genuinely care about the project and you can find really interesting articles and even some interactive stuff even though gemini was not built to upload complex data.
Privacy is an important part of Gemini so all connections must use TLS. Gemini uses the TOFU (Trust on First Use) principle and treats the self-signed certificates as first-class citizens. Gemini also has a document format called gemtext which is a very simple alternative to HTML and markdown. Writing parsers for gemtext is very easy because it is line-oriented. Each line is a type, for example, lines beginning with => are links and lines beginning with # are headings.
Writing the server and the crawler
I decided to write a very simple library in Go, similar to net/http to write Gemini servers. You can find the library here. I then built a server (gemserver) using this library.
In Gemini sending inputs is interesting. When the client requests a resource, the server responds with a status 1x and a <META>. The client software looks at the status code and shows an input prompt to the user with the <META> as the label. Once the user enters the input, the client requests the same resource with the input as a query component.
I also wrote a very simple Gemini client which I then used to build a basic BFS crawler (gemini-crawler). The crawler has a small parser to read and collect Gemini links which are added to a queue to be visited later. I am using bleve which is an awesome indexing library written in Go. It is lightweight compared to something like ElasticSearch and performs really well. The code for the crawler can be found here.
AWS Setup
I kept the architecture simple. This is my first time using AWS so it took me some time to figure out which services I will be using. It is quite overwhelming with so many offerings and seemingly many offerings doing the same thing? I had to also figure out if those services would fall under the free tier.
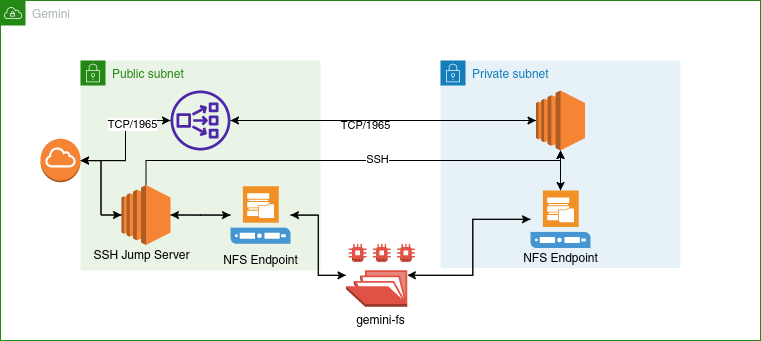
My initial plan was to run everything in an EC2 instance, but then I realized that it is not a good idea to directly expose a VM to the internet. So then, I created 2 subnets in the same availability zone, one private and another public. I placed a network load balancer in the public subnet which listens on port 1965 and forwards the traffic to the EC2 machine in the private subnet. The private subnet doesn’t have a NAT gateway so it is completely isolated from the internet. The only way to access it is via a jump server which is in a public subnet with ssh hardening in place. I turn the jump server off when not needed.
The gemini-crawler resides in the jump server as a service. It is configured to autostart, so whenever I start the server, it starts indexing. Each indexing run creates a new index folder in the shared Elastic File System.
Gemserver is configured to use an IndexAlias where it can load multiple different indices and search across them.
Conclusion
It was a fun project and I got to learn a lot about AWS and Gemini. I also tried my hands at Go profiling using pprof to improve the performance of the crawler. There are a few more things that need to be done
- Create a larger index. The current index is very small which decreases the relevance of the search results.
- Optimize the crawler. The crawler can be further optimized, the indexing component is slower than the link extractor component so even if the crawler can find a lot of links, all of them might not be available in the index. I also noticed that the memory usage keeps on increasing and the OOM killer kills the process after a few hours.
- Add some ranking to the search results. Currently, the results are ranked using bleve’s internal tf-idf ranker.